Project Description
What is LangLens?
a free, AR language learning web-app, accesible from any mobile device with a camera and internet access, designed to make learning a new language as interactive
Imagine you want to learn a new language. Recent advances in technology have progressed the world into an era of unlimited access to information and endless potential from a device that a majority of people carry in their pockets. Why not enhance the ability to learn a new language by ditching the textbooks and simply scanning the environment around you to see the world change into the language you are trying to learn right before your eyes? Or even better, interact with this augmentation of reality by saving what you see into digital flashcards and mastering languages all from the touch of a screen?
Our client, Dr. Okim Kang, is a professor in the Department of English at Northern Arizona University with special emphasis in Applied Linguistics and TESL (Teaching English as a Second Language). She has published numerous academic books and journals covering a wide range of research topics surrounding language learning and language teaching, and she has also been awarded with several honors regarding her outstanding contributions to the research and innovations of TESL and language pedagogy.
Dr. Okim, and her team, have been working in Computer-Assisted Language Learning (CALL) for several years and have observed a significant lack of tools targeted towards foreign language learners that utilize the latest advances in AR technology. A majority of language learning tools that are currently on the market, for example Duolingo or Mondly, only include a few aspects of speech and language pedagogy and fail to modernize their tools by rarely providing both object detection and optical character recognition (OCR) functionality. To fill this market gap, LangLens has partnered with Dr. Okim to create an innovative, web-based tool, designed for all mobile devices, that provides a free-to-use, immersive, language learning experience employing both object detection and text recognition capabilities with the latest AR technology available.
Problem Statement
A majority of language learning tools that are currently on the market only include a few aspects of speech and language pedagogy and fail to modernize their tools by rarely providing both object detection and optical character recognition (OCR) functionality.
This project would serve as an independent tool, not necessarily a part of an already existing production flow, as LangLens would be creating a unique computer-assisted language learning tool. While there are many language learning tools that dabble with augmented reality, they all have certain deficiencies, missing capabilities, or limitations such as:
Solution Vision
The following features of the LangLens solution aim to employ recent advances in object detection and optical character recognition (OCR) via detection modes that the user can toggle between upon opening the application.

System Architecture
We designed a three-tier client server architecture using Bootstrap for our frontend and Django for our backend. When users access the site, they will have the option of toggling between two detection modes that are prompted on the UI: Text Mode and Object Mode. Users will also need to select their target language for translation. The currently available languages on our web-app include Spanish, English, French, Korean, and Chinese. The frontend UI will be constructed using Bootstrap and will be able to communicate to the Django backend for either mode selected and will also communicate with the detection engines to indicate which language and model to use based on the user's target language preference. If this the user's first time accessing our web-app, they will be prompted with a permission request for access to their mobile camera. This permission is a major factor in whether or not the application will function as if the user declines camera access no further process will be initiated for personal security purposes
Last updated 4/26/2023
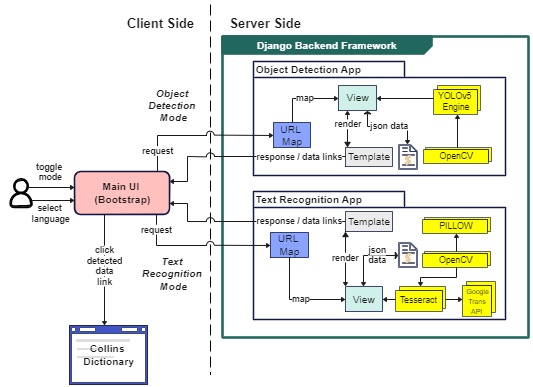
1. Text Mode Case: If the user selects Text Mode, the camera will begin scanning the environment that the user provides with their mobile back camera. The user can hit the Guide button on the GUI to display instructions on how to use Text Mode. They can also choose 1 of the 5 available target languages for translation. Finally, the user can aim their device at the word(s) they would like to scan and translate and hit the blue Detect button. This takes a picture of the user's current environment and sends an AJAX POST request from the Template to the View containing the base64 encoded image and the user's target language. The View preprocesses the image with OpenCV, sends it to pyTesseract for text recognition and extraction, and is then returned as an array containing any detected words in the image and their bounding box coordinates. The text is then translated to the user's target language with GoogleTrans API and drawn onto the original image with PILLOW using the obtained bounding box coordinates. The image is saved into the server's static files and the URL path of the image as well as the language and the bounding box coordinates are returned back to the Template as a JSON response. The response data is finally rendered to the Template AFTER the frontend JavaScript transforms the bounding boxes around the words in the image as clickable links to the Learning Page (CollinsDictionary.com). If the use clicks on any of the bounding boxes in the result image, they will be redirected to the Learning Page and shown a correct definition, word-in-use guide, and pronunciation of their desired word from their target language to English.
2. Object Mode Case: If the user selects Object Mode, the camera will begin scanning the environment that the user provides with their mobile back camera. The user can hit the Guide button on the GUI to display instructions on how to use Object Mode. They can also choose 1 of the 5 available target languages for translation. Finally, the user can aim their device at the object(s) they would like to scan and translate and hit the blue Detect button. This takes a picture of the user's current environment and sends an AJAX POST request from the Template to the View containing the base64 encoded image and the user's target language. The View preprocesses the image with OpenCV and sends it to YOLOv5 to identify the objects in the image with our custom trained language object model (unique for each language). The YOLO algorithm then returns the detected object(s) bounding box coordinates, confidence scores, and result image as a JSON response. The response data is then finally rendered to the Template AFTER the frontend JavaScript transforms the bounding boxes around the object(s) in the image as clickable links to the Learning Page (CollinsDictionary.com). If the use clicks on any of the bounding boxes in the result image, they will be redirected to the Learning Page and shown a correct definition, word-in-use guide, and pronunciation of their desired object's label from their target language to English.