Main Page
Title Page
Executive Summary
Project Overview
Installation Guide
Users Guide
4. Architecture / Design
4.1 Design / Development Process
The development paradigm we used for our project was the Incremental Process.
We developed our program in layers. For each layer we first determined how it
should look, in the case of GUI elements, or how it should be structured, for
the underlying code. Then we did a more detailed design of the modules:
deciding function names, what functions handle what, and how they interact.
Unfortunately we didn't write most of this stuff down. We just put it into
our program files as we made these decisions.
The next step for the layer was writing the code. As we finished each module
we did white box testing to make sure it works correctly. Then we integrated
the modules for a layer and integrated that layer with any previous layers that
it needed. Finally, we did black box testing to find any bugs and correct
problems before we moved on to the next layer.
The incremental layers we used went from the skeleton of the GUI down to deeper
levels of underlying code and then to extra features. First we created a
resource framework for our GUI. The next layer was the code to control
resources, get information like user input, and display and edit the Doc list
and text field. Next was the code for category support. Then we did the low
level Doc-format decompress and compress algorithms. The next layer was for
opening, displaying, scrolling through, and saving a Doc. Finally, we
implemented a few of the extra features, like copy, cut, and paste and
beaming.
4.2 Program Architecture
The Architecture of our program is best illustrated with two diagrams. One
diagram is for our GUI, that shows the two main screens of our program and
what options are available to the user from each. The other diagram shows the
underlying structure of the part of our program that relates to opening,
scrolling through, and saving a Doc file.
Diagram 1: GUI Architecture

The Doc List and Doc View screens are the two main event handlers for our
program. The arrows show how you switch between the two screens by opening
and closing a Doc. The lines with diamonds on the end show where you can
access these options and features from. The Database Operations represents
the buttons we have across the bottom of our Doc List screen. The Doc Menu
can be accessed from the Doc List menus or Doc View menus, but they are not
identical in each. The two Doc Menus do have certain things in common like
preferences, beaming, and our about box. We currently don't have searching
or bookmarks implemented, but we left them on our menus so that we might be
able to get them working in the last two weeks. Also, after the semester is
over one of us might want to continue the GNU project. Our preferences menu
item is the same. It's where somebody might put things like variable speed
scrolling and other program options.
Diagram 2: Doc Control Architecture
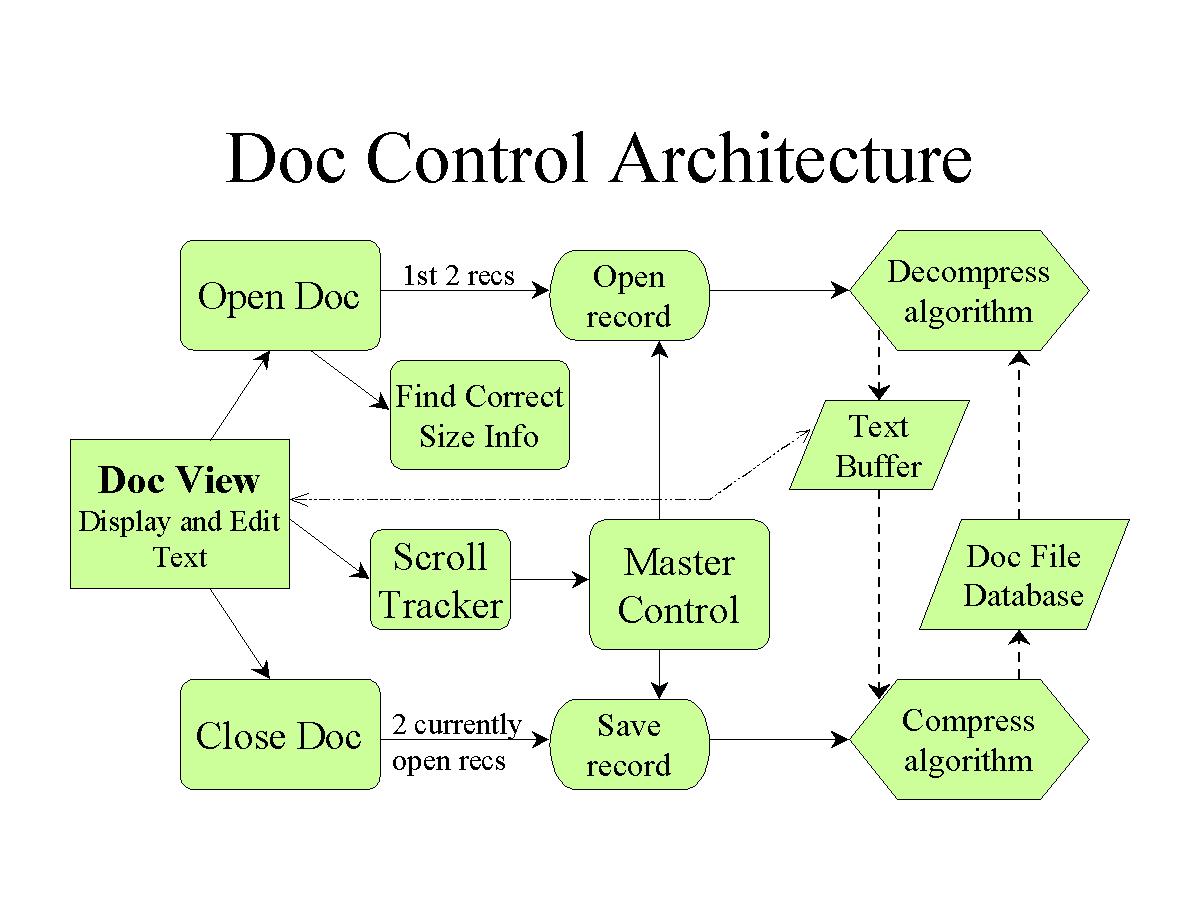
This diagram illustrates the structure of the underlying part of our program.
The Doc View screen is the element of the GUI that the whole control structure
interacts with. The solid arrows basically represent function calls, or how
the flow of control is passed between different components. The dashed arrows
show data movement between the Doc file and the text buffer through the
decompress and compress algorithms. The other, different, dashed line shows
that what is contained in the text buffer is displayed in the Doc View screen.
Since memory is very limited on the palm, we are only opening two records
(approximately 8K) at a time. This reason necessitates the complex structure
we implemented.
When a Doc is first opened, Open Doc gets access to the database, finds the
correct size information and creates an array that holds the decompressed
size of each record in a Doc. It then opens the first two records. Open
record is a function that deals with all the API stuff needed to get a
record, lock it so it doesn't get moved, and find the compressed size.
Then it calls the algorithm to decompress the record into the text buffer.
The Save record function is analogous to Open record. We tried to keep the
decompress and compress algorithms as non-system-dependent as possible so
that they can easily be ported to other platforms.
After the Doc is opened, as a user scrolls through the text in the Doc View
screen the Scroll Tracker watches what line you're on and if any editing
has been done. When the scroll gets down to the end of the two open records
it calls the Master Control. The Master Control deals with closing the 1st
record, and saving it if it's been edited, then opening the second record and
the next one to open into a new buffer. It has to deal with adjusting
record boundaries if the size has been changed and adding/deleting records
as necessary. When the user wants to close the Doc, the two currently open
records are saved if they've been edited and the Doc header information is
updated. Then the control goes back to the Doc List screen.
Maintenance Guide
Post Mortem