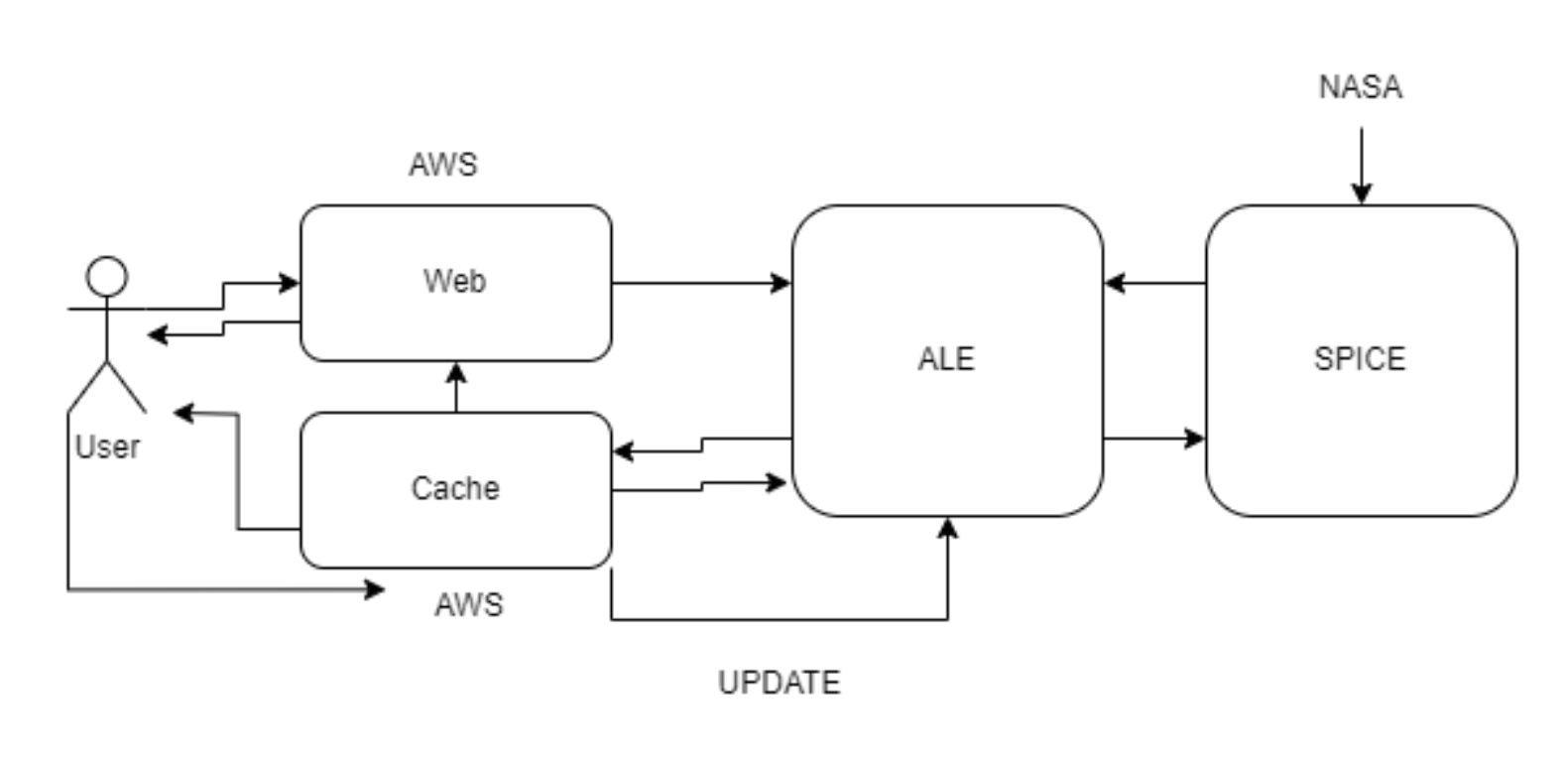
RESTful Web Service:
The solution involves building a Python-based web service using frameworks like Flask or FastAPI. This service will provide a user-friendly interface for requesting ISD data without needing deep knowledge of SPICE or ISD internals. It will act as a bridge between the user and the ALE library, managing requests and responses seamlessly.
Data Compression and Format Optimization:
To address the challenge of large JSON data sizes, the service will implement a data compression mechanism, potentially using formats like gzip or custom binary formats to reduce the size of ISD files. This approach aims to reduce the data transfer time and storage space while maintaining the integrity of the ISD data.
Scalability and High Availability:
The service will be designed to scale horizontally, allowing it to handle multiple simultaneous ISD requests. This will involve optimizing the backend to manage concurrent requests and leveraging AWS infrastructure for load balancing and auto-scaling, ensuring that the service can meet the demands of high-powered computing environments.
AWS Integration:
The prototype will be deployable on AWS free-tier services, using EC2 or AWS Lambda for hosting, and S3 for storing the reduced ISD data. The service will be configured for cost-efficiency and ease of use, making it accessible for both testing and production environments.
Queryable ISD Data Store (Stretch Goal):
As an extension of the caching solution, the project will develop a queryable data store, allowing users to access cached ISD data efficiently. This solution will involve creating an index or metadata catalog to quickly retrieve stored ISD data, streamlining access for large-scale research.