Project Description
Our project was initially sponsored by Western Digital, but due to unforeseen circumstances, we lost their support. We are grateful to our former client, Rajpal Singh, for providing the original concept for this project.
Modern solid state drives suffer from "Silent Errors", essentially when a portion of a drive fails without warning, causing lost files, corrupted data, and dead drives. This is a big issue for companies like Amazon, running AWS services on tens of thousands of SSD's. Drive manufacturers are trying to figure out a way to detect silent errors, and prevent them from causing issues for industry customers in the future, however, their current approach is so inefficient, any progress is highly unlikely.
In order to make this process more efficient, we were tasked to develop an Observability, Analytics, and Insight platform for SSD manufacturers. Our platform probes the hard drive of the system running the program, collecting data, storing it, and sending it to a visualization dashboard for analysis. This allows clients to easily collect and analyze performance metrics that reveal silent errors.
When implemented, our platform collects kernel-level data easily, allowing for non-kernel experts to work on the issue. The project was structured as our former client envisioned, with both a back-end and a front-end team. The back-end team is responsible for collecting, analyzing, compiling, and delivering the data to the front end. The front-end team then unpacks, organizes, and distributes the data among the appropriate databases before sending it to the visualization dashboard.
This platform will make detecting silent errors feasible, improving SSD's and saving manufacturers time and money. Once the program is completed and refined, it can be marketed to companies to meet their specific needs and directions. The initial concept for this project was provided by our sponsor, in the form of a PDF: Capstone project proposal.
High-Level Requirements
Key Requirement Thresholds
- Repeated Collection of Data from Data Centers
- Pipeline between Data Center Collection to Cloud Databases
- Analysis of Data in Cloud Databases
- Display of Data from the Cloud Databases
- Alert of Data of Interest at the Display level
- Automation of Program
Functional Requirements
- Automated Data Collection
- Versatile SSD Probing
- Flexible Data Collection
- Automated Data Transmission
- Cloud Storage Organization
- Data Querying and Processing
- Malleable Data Analytics
- DAta Observability Dashboard
- Automated Error Handling and Debugging
For more information about this, please visit the Documentation Tab and access the Requirements Document.
Expected Milestone Progression
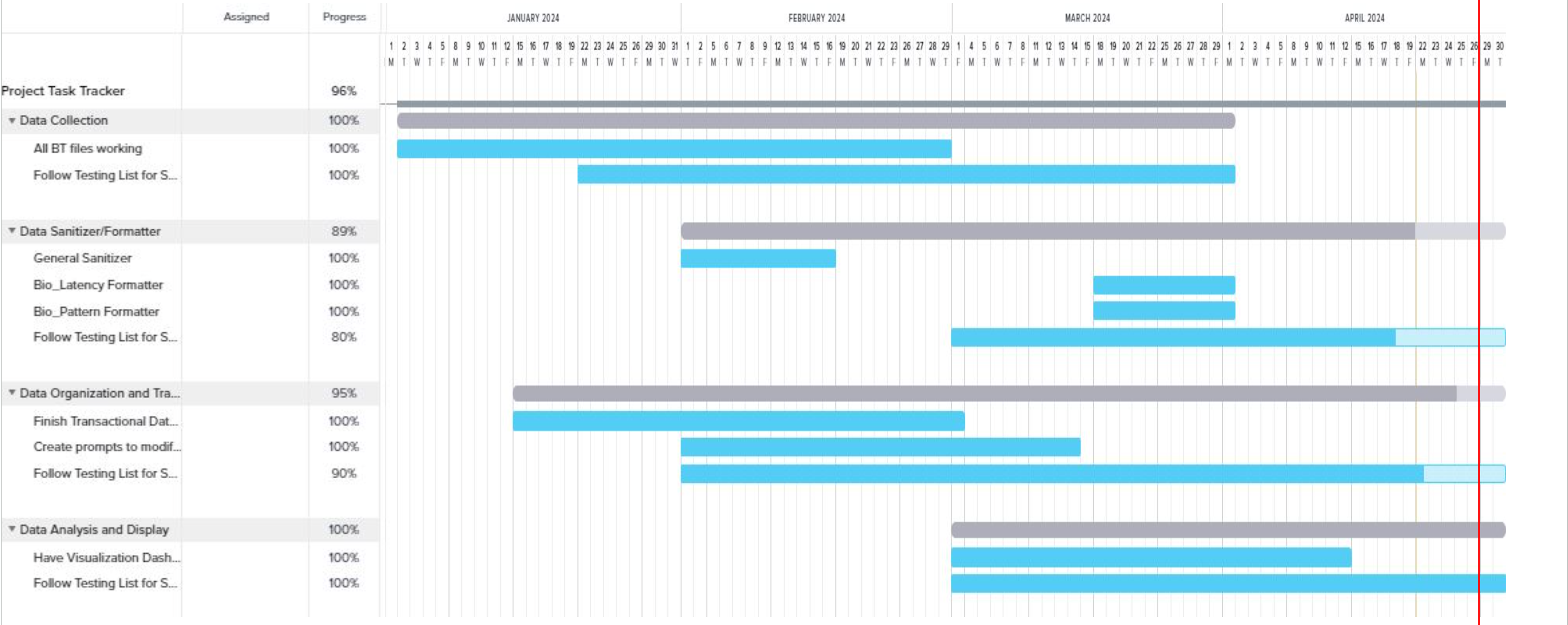
The Gantt chart above outlines the timeline for our project milestones. Initially, we focused on data collection to populate the rest of the program with dummy data. Next, we developed the sanitizer/formatter and database in tandem, using example outputs. Once these were complete, we built the visualization dashboard, which is fed data from the database. Throughout this process, we conducted ongoing testing to ensure that all functionalities were refined before integration into the main system. Completion of these milestones is crucial for achieving the Minimum Viable Product (MVP), and any stretch goals should be deferred until then.
Resources
- eBPF Documentation: Official documentation providing an overview of eBPF and its capabilities.
- eBPF Tracing Tools: A collection of eBPF tracing tools curated by Brendan Gregg.
- BPF Performance Tools: Resources on performance tools using BPF, recommended by Brendan Gregg.
- AWS Documentation: Official documentation for various AWS services, providing in-depth information on usage and configuration.
Solution
We developed a robust data collection and pipeline software for user-friendly display. The plan involves using eBPF, C++, and Python for data collection, with Python responsible for compiling and delivering data in JSON/CSV format. After delivery, a master MySQL database will be created, housing device information and additional tables derived from the eBPF collection. Once the data is stored, a Flask server will query the data and feed it directly into a Svelte app. This app will utilize D3 Designs to create relevant graphs for the client.

Technologies
- eBPF (Required):
- iovisorToolsKit (Required):
- mySQL
- Flask Server
- Svelte App + D3
- Discord (Communication):
- Google Drive (Documentation Sharing and Storage):
- VSCode (IDE):
- Linux based VM (Ubuntu 22.04):
- Git/Github (Version Control):
Data analysis software tools and packages used to extract data about the kernel. This is an important software as this would be collecting all data to be used for the client and give ranges of information about the kernel level depending on the object that is being analyzed. To learn more about eBPF, follow this link here. This is one of the main activities that the project is using. With the results given from the eBPF data mining, it will mine information ranging from the Bio latency, errors, NVME and such. All of this will be organized and displayed for the user to efficiently understand what is happening to the kernel, giving possible answers to improve their performance on their product.
An extension of the eBPF. This would have coding examples, tools, and objects to help learn, analyze, and work with eBPF. It also formats the data collection to be read more easily by the eBPF user.
Database that stores and serves collected performance data and drive metadata.
Queries mySQL database for data requested and serves it to the visual dashboard.
Svelte app provides the interface for the user to select desired drives, test runs, and performance metrics to display. For visualization, data is processed, formatted, and inserted in D3 objects, automatically building required graph components.
An application of communication amongst the team members. This is considered the best and easiest way to communicate with each other as the application is capable of instant messaging, phone and video calls, organization, bot reminders and so on.
A collaborative cloud drive that the team members would all use to work and store documentation, code, and presentations. Items will vary as deliverables will be continued but this would be the main place for any form of documentation.
Chosen for it’s easy to use interface and clearness of code as well as ensures everyone uses the same environment. Would contain mainly the python3, C code, and queries that would be attached to the databases. The issue with just this is the use of eBPF (described later) since eBPF needs to run in the command line and is required to look within the system.
Used for everyone having the same Operating System and also the important software eBPF being used in this environment. All activities would be located in everyone’s virtual machine in order to achieve similar functionality. This is used in the final product as this is the main system that most of the data mining software activities are located at
Intended to keep version control and have everyone share the code that is produced. This will have a range of things ranging from code, deliverables, stored data, licensing, etc. This will be helpful in replicating the repository in everyone’s systems so that things can continue being worked on.
Tech Demo
The video walkthrough of our program is divided into five parts, each representing a step in our solution:
- Probing and Collection: The program collects data from various BT files (Block RQ Complete + Error, Bio Latency, Bio Pattern) and device-specific data. This data is stored in CSV or Text files.
- Data Sanitization/Formatting: The CSV and Text files are cleaned and formatted to be easily readable and interpretable by both humans and machines. The cleaned data is then stored back into CSV files.
- Database Upload: The cleaned data from each file is uploaded to the appropriate tables in a MySQL database. The data related to the device being probed is also uploaded and linked with the collected data to maintain their association.
- Data Querying and Populating: The data from the database is queried and sent to the visualization dashboard. This is facilitated by a Flask server, which establishes the connection between the database and the dashboard.
- Visualization Dashboard: The queried data is displayed on the dashboard using a Svelte app and D3 designs. This allows the user to explore the data based on the BT files used.
Codebase
Here is the codebase for the Capstone Project. This includes our Minumum Viable Product, website, and deprecated AWS code: GitHub